








業務自動化の現場で注目されているのが「XPath」です。XPathには、一般的なプログラミング言語とは異なる利用条件や独自のルールがあります。XPathを正しく活用するためには、まず基本事項を押さえることが大切です。
本稿では「XPathとは何か」という基本から、用途や必要な環境、ルール・書き方まで、まとめてお伝えします。XPathの活用を検討している方は、ぜひ参考にしてください。
- もくじ
1. XPathとは:HTMLやXMLからデータを取得するための言語
XPath(エックスパス)とは、HTMLやXMLといった言語で構造化された文書(コード)の中から、特定のデータを取得するための言語です。複雑な文書の中から、目的の情報へたどり着くための「道順」を正確に表現する役割を担います。
- HTML(HyperText Markup Language):Webページのコンテンツや構造を定義する言語。
- XML(Extensible Markup Language):データを構造化し、効率的にやり取りするための言語。
HTMLやXMLでは、「タグ」と呼ばれる目印で<タグ名>データ</タグ名>のようにデータを挟み、階層構造を作る特徴があります。例として、簡単なWebページを表示するHTMLは下記のとおりです。
<html>
<head>
<title>サンプルページ</title>
</head>
<body>
<h1>ようこそ!</h1>
<p>これはサンプルの段落です。</p>
</body>
</html>
この中から、たとえばWebページのタイトル(titleタグの中身)を取得したいとしましょう。このときXPathを使うと、下記のように表現できます。
/html/head/title
このように、要素への「道順」をコードとして表現できるのがXPathです。
2. XPathの主な用途
XPathは、さまざまなシーンで利用されています。XPathの主な用途は、次の3つです。
- データ連携
- Webスクレイピング
- 業務自動化
2-1. データ連携
異なるシステム間でデータをやり取りする際には、XML形式がよく使われます。XPathを使えば、構造化されたXMLの中から特定のデータをピンポイントに取得できます。たとえば、外部システムから受信した書籍データを文書管理システムに取り込みたい場合、XPathで著者名や出版社といった情報を個別に取得できます。
2-2. Webスクレイピング
XPathは、Webページから情報を抽出する「Webスクレイピング」で大いに役立ちます。たとえば、商品一覧ページから商品データを収集する際、Webスクレイピング用のスクリプトを使えば、収集作業の大幅な効率化が図れます。このとき、商品の名前や価格といった情報を正確に指定するために、XPathがよく使われます。
2-3. 業務自動化
日々のルーティンワークの中には、Webページ上で決まった操作を繰り返すような業務も少なくありません。こうした業務を自動化する際にも、XPathが便利です。たとえば、特定のボタンや入力欄を自動で操作したい場合、その要素の位置を正確に指定する必要があります。XPathを使えば、ボタンや入力欄を文書の構造に沿ってピンポイントに指定し、プログラムによる制御を可能にしてくれます。
以前の業務自動化では、マウスの座標やキーボード操作の位置を手動で指定する手法が一般的でした。しかし、この手法ではWebページのレイアウト変更に影響を受けるのが大きな難点です。その点、XPathを使えば画面の見た目に左右されず、構造に沿って対象要素を指定でき、より柔軟な自動化が可能になります。
3. XPathを使える主な環境
XPathは、HTMLやXMLのデータを表現する際のルールを言語にしたものです。ただし、それ単体で動くわけではありません。XPathで記述された「道順」を実際に処理するためには、それを解釈して実行するための環境が必要です。ここでは、XPathを使える主な3つの環境について解説します。
3-1. Webブラウザ
Webブラウザは、HTMLで書かれたWebページを解釈し、画面上へ表示するソフトウェアです。XPathを処理して直接動作させる機能はありません。しかし多くのWebブラウザには、Webページ内の特定要素からXPathを取得したり、XPathで要素を検索したりする補助機能が備わっています。
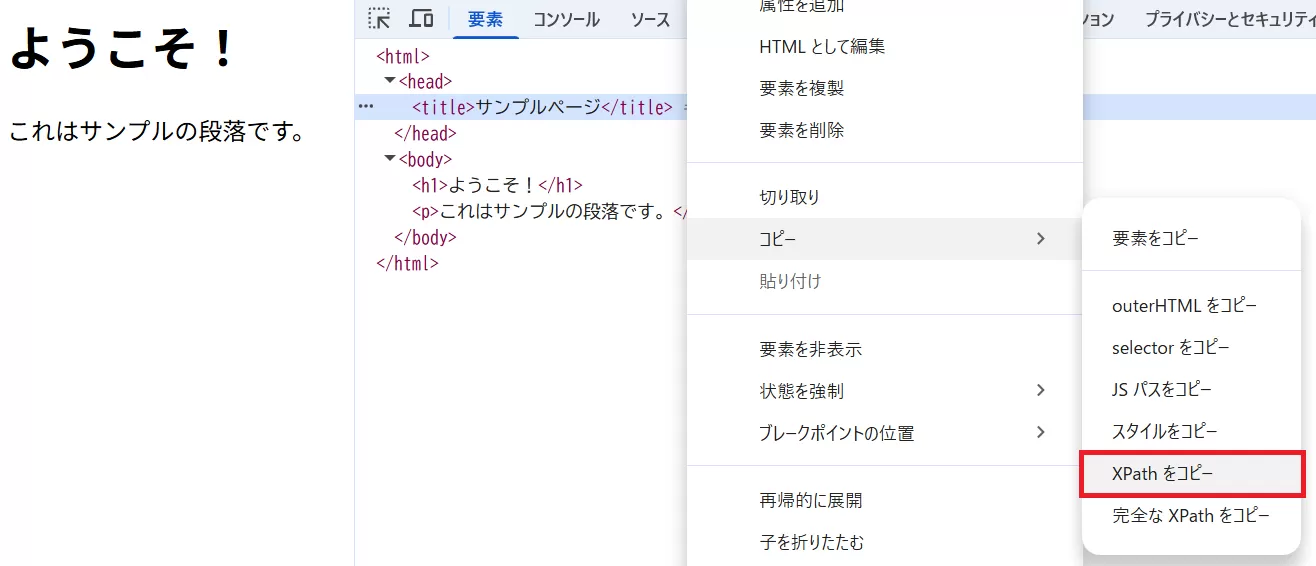
たとえば「Google Chrome」では、画面上で右クリックして「検証」を選ぶと、開発者ツールが表示されます。そこからHTML要素にカーソルを合わせて右クリックし「XPathをコピー」を選ぶと、その要素を参照するXPathを取得できます。
3-2. プログラミング言語のライブラリ
PythonやJavaなど、多くのプログラミング言語には、XPathを効率的に活用するための「ライブラリ」があります。ライブラリとは、特定の機能を手軽に使えるように部品化したプログラムのことです。
たとえばPythonライブラリ「lxml」を使えば、Pythonプログラム内でXPathを処理できます。lxmlは、HTMLやXMLをプログラムの中で扱いやすい形に変換し、XPathの構文を解釈して必要なデータを取得してくれます。
プログラムの中でXPathを使えるようにするライブラリは、Webスクレイピングや業務自動化のカギとなります。
3-3. 各種専用ツール
Webスクレイピングや業務自動化などに関する専用ツールには、XPathの機能を搭載しているものが多くあります。特にRPA(Robotic Process Automation)ツールには、XPathに対応した製品が珍しくありません。
たとえばRPAツール「UiPath」では、Webページ上の操作を自動化する際にXPathが活用されています。特定のボタンや入力欄などを選択すれば、ツールが自動的にXPathを生成するため、対象の要素を正確に識別できます。
このようなツールを使えば、プログラムを記述せずともXPathの仕組みを活かしながら、効率的に業務を自動化できます。
4. XPathの基本的なルールと書き方
XPathを活用するためには、基本的なルールと書き方を押さえることが大切です。ここではサンプルコードを交え、XPathの基本的な5つの書き方を紹介します。
4-1. /(スラッシュ)で階層構造を表現する
XPathでは、スラッシュ(/)で階層構造を表現します。たとえば、冒頭で紹介した下記のXPathでは、html > head > titleという3階層を表現しています。
/html/head/title
これは最も基本的な記述ルールであり、XPathを使ううえで欠かせません。
4-2. //(二重スラッシュ)でどこからでも検索できる
XPathでは、二重スラッシュ(//)を使うことで、指定した要素がどの階層にあっても検索可能です。たとえば次のXPathは、文書内のどこかに存在する「divタグ直下にあるpタグ」を指定します。
//div/p
複数のdivタグが存在する場合、それぞれの直下にあるpタグが対象になります。階層を気にせず柔軟に検索したいときに便利です。
4-3. [](角括弧)で条件を絞り込む
XPathでは、角括弧([])を使うことで、要素の中から特定の条件に合うものを絞り込めます。たとえば次のXPathは、/html/body/div/ul直下に複数あるliタグのうち、2番目のものを取得できます。
/html/body/div/ul/li[2]
同じタグが複数ある場合、数字で順番を指定することで、必要な要素を正確に取り出せます。
4-4. @(アットマーク)で属性を指定する
XPathでは、アットマーク(@)を使うことで、要素の属性を指定できます。属性とは、<タグ名 属性名="値" >といった形でタグ内に指定する補足情報です。
たとえば次のXPathは、id属性が「name」であるinputタグを取得します。
/html/body/div/input[@id="name"]
前述の角括弧と組み合わせることで、より細かいデータが取得できます。
4-5. text()関数でテキスト情報を取得する
XPathのtext()関数を使うと、要素の中に含まれるテキスト情報を取得できます。たとえば次のXPathは、h2タグ内のテキストを取り出します。
/html/body/h2/text()
仮に、該当のh2タグが<h2>目次</h2>となっていた場合、「目次」というテキストを取得できます。画面に表示される文字情報だけを扱いたい場合に役立ちます。
5. まとめ
XPathは、HTMLやXMLから特定のデータを取得するための便利な言語です。Webスクレイピングや業務自動化、データ連携など、さまざまな用途に活用できます。
XPathを有効活用するためには、基本ルールを理解し、正しい環境を使用することが大切です。XPathを取り入れる際には、今回の内容をぜひ参考にしてください。














